







Written by: Oğuzhan Furkan Aslan
Introduction
This article explores the creation of an ETL (Extract, Transform, Load) application using Streamlit, a powerful and user-friendly Python library for building web apps. ETL processes are essential for data integration, helping businesses improve the quality, reliability, and usability of their data. This guide provides a step-by-step approach to building a custom ETL app tailored to specific use cases, showcasing how Streamlit can be leveraged to streamline data processing tasks efficiently. Whether you are new to ETL or looking to enhance your data management skills, this article will equip you with the knowledge to build a robust ETL application.
What is ETL?
ETL is a data integration process that involves Extracting, Transforming, and Loading data from one source to another. Companies favor ETL for its ability to enhance data quality, reliability, and usability.
Streamlit ETL App
To build this ETL app, use any Python IDE or even GitHub. The example here uses VS Code.
Installation Requirements:
pip install streamlitBuilding the App:
- Import Necessary Libraries:
- Start by importing the necessary Python libraries. Since this is a simple app, Streamlit and Pandas libraries are sufficient.
import streamlit as st
import pandas as pd
- App Title and Caption:
- Name the app with the Streamlit title function. Then add a caption to explain the app’s functionalities through the Streamlit caption function. (Supporting documentation: streamlit title function, streamlit caption function)
st.title("The Streamlit ETL App 🗂️ ")
st.caption("""
With this app you will be able to Extract, Transform and Load Below File Types:
\n1.CSV
\n2.JSON
\n3.XML
\nps: You can upload multiple files.""")
- The app will have the below functionalities:
- Read CSV, JSON and XML file types.
- Extract the data from these file types.
- Transform the data as required.
- Save and download it as CSV file.
- File Upload and Processing:
- Since files will be received from the user, the Streamlit file uploader function will be useful. Next, the pandas library will be utilized to read the uploaded files, place them into an empty data frame, and then merge them.
This allows users to upload multiple files, facilitated by the file_uploader function. (Supporting Documentation: Streamlit File Uploader)
uploaded_files = st.file_uploader("Choose a file", accept_multiple_files=True)
# let's create a function to check the file types and read them accordingly.
def extract(file_to_extract):
if file_to_extract.name.split(".")[-1] == "csv":
extracted_data = pd.read_csv(file_to_extract)
elif file_to_extract.name.split(".")[-1] == 'json':
extracted_data = pd.read_json(file_to_extract, lines=True)
elif file_to_extract.name.split(".")[-1] == 'xml':
extracted_data = pd.read_xml(file_to_extract)
return extracted_data
# create an empty list which will be used to merge the files.
dataframes = []
- File Handling and Data Transformation:
- This is a simple, straightforward method to verify the file format and read it with pandas functions. Uploaded files will be retrieved, and logic will be applied to read, merge, and transform them. The extraction process is more standardized than the transformation process. Standard file types can be obtained during extraction, but each file may have different use cases. A standard approach to transforming the data can be adopted by leveraging the functionalities provided by the Pandas library, specifically focusing on removing null values and duplicates. 🐼🔍
if uploaded_files:
for file in uploaded_files:
file.seek(0)
df = extract(file)
dataframes.append(df)
if len(dataframes) >= 1:
merged_df = pd.concat(dataframes, ignore_index=True, join='outer')
remove_duplicates = st.selectbox("Remove duplicate values ?", ["No", "Yes"])
remove_nulls = st.selectbox("Remove null values in the dataset ?", ["Yes", "No"])
if remove_duplicates == "Yes":
merged_df.drop_duplicates(inplace=True)
if remove_nulls == "Yes":
merged_df.dropna(how="all", inplace=True)
show_result = st.checkbox("Show Result", value=True)
if show_result:
st.write(merged_df)
csv = merged_df.to_csv().encode("utf-8")
st.download_button(label="Download cleaned data as csv",
data=csv,
file_name="cleaned_data.csv",
mime="text/csv")
Explanation of the above Code:
- File Upload Verification:
- Checks if any files are uploaded.
- Iterates over uploaded files, sets the file cursor to the beginning, extracts data, and appends to a list.
- Merge Data Frames:
- Merges multiple data frames if more than one file is uploaded.
- User Interaction:
- Allows users to remove duplicates and null values based on their selection.
- Display Result:
- Provides an option to display the final merged data frame.
- Export Cleaned Data:
- Converts the cleaned data frame to CSV and provides a download button.
- Final Code Block:
import streamlit as st
import pandas as pd
import xml.etree.ElementTree as ET
from datetime import datetime
st.title("The Streamlit ETL App 🗂️ ")
st.caption("""
With this app you will be able to Extract, Transform and Load Below File Types:
\n1.CSV
\n2.JSON
\n3.XML
\nps: You can upload multiple files.""")
uploaded_files = st.file_uploader("Choose a file", accept_multiple_files=True)
def extract(file_to_extract):
if file_to_extract.name.split(".")[-1] == "csv":
extracted_data = pd.read_csv(file_to_extract)
elif file_to_extract.name.split(".")[-1] == 'json':
extracted_data = pd.read_json(file_to_extract, lines=True)
elif file_to_extract.name.split(".")[-1] == 'xml':
extracted_data = pd.read_xml(file_to_extract)
return extracted_data
dataframes = []
if uploaded_files:
for file in uploaded_files:
file.seek(0)
df = extract(file)
dataframes.append(df)
if len(dataframes) >= 1:
merged_df = pd.concat(dataframes, ignore_index=True, join='outer')
remove_duplicates = st.selectbox("Remove duplicate values ?", ["No", "Yes"])
remove_nulls = st.selectbox("Remove null values in the dataset ?", ["Yes", "No"])
if remove_duplicates == "Yes":
merged_df.drop_duplicates(inplace=True)
if remove_nulls == "Yes":
merged_df.dropna(how="all", inplace=True)
show_result = st.checkbox("Show Result", value=True)
if show_result:
st.write(merged_df)
csv = merged_df.to_csv().encode("utf-8")
st.download_button(label="Download cleaned data as csv",
data=csv,
file_name="cleaned_data.csv",
mime="text/csv")
Running a Demo of the App
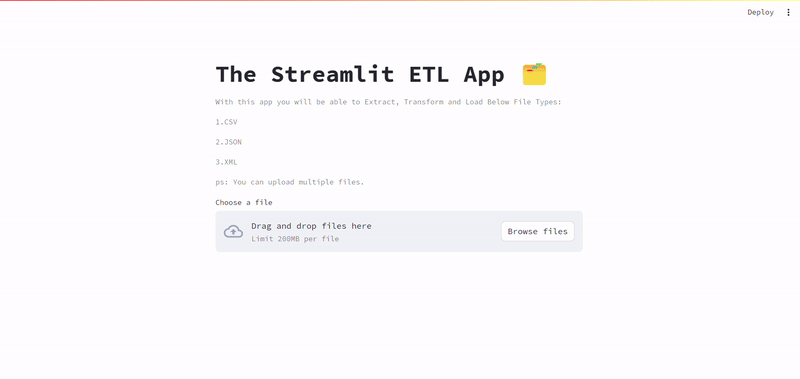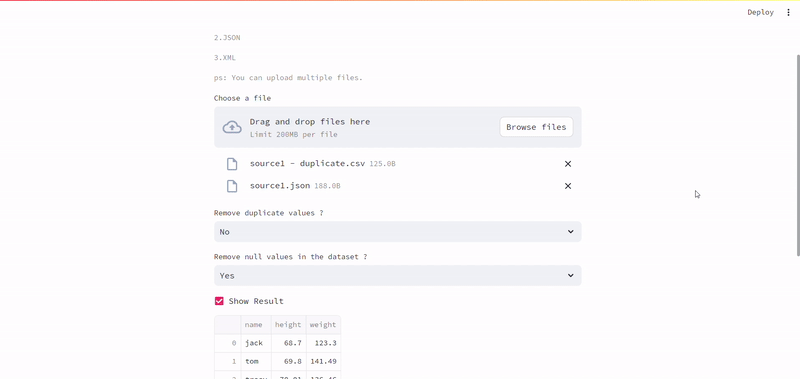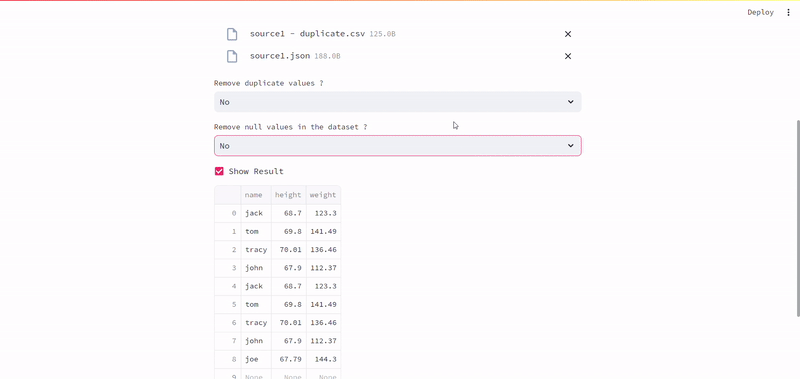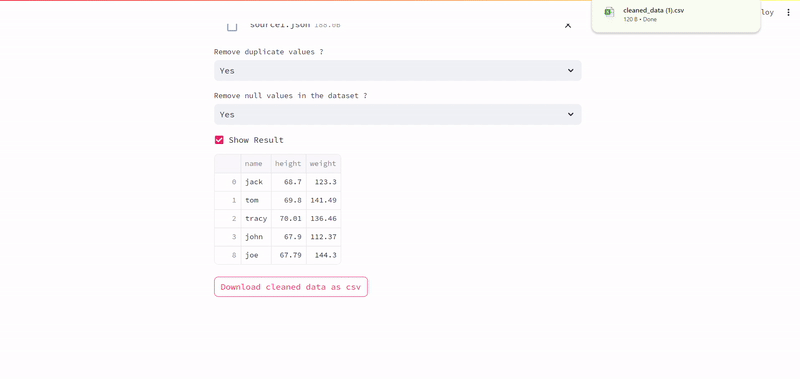
Deploy the app on Streamlit Cloud and share it publicly. First add the app to GitHub, connect it to Streamlit Cloud, and deploy it.
For detailed guidance, refer to the Streamlit documentation on deploying apps.
Conclusion
Building an ETL app with Streamlit demonstrates the versatility and ease of use of this Python library for data processing tasks. By integrating functionalities like file uploading, data extraction, transformation, and downloading cleaned data, Streamlit simplifies the ETL process, making it accessible for users with varying levels of programming expertise. This guide has shown how to construct a functional ETL application, paving the way for further customization and enhancement based on individual requirements. As businesses continue to prioritize data-driven decision-making, mastering tools like Streamlit will be invaluable in managing and optimizing data workflows efficiently.